

New, deeply integrated AI-powered productivity tools are on the horizon. A recent example is Microsoft’s Recall, but others are also emerging. For example, there’s Limitless.ai, and if you are feeling particularly nostalgic for Catholicism, there’s the 01 Light from Open Interpreter, which allows you to control your computer remotely through a communion wafer.

All of these tools promise infinite productivity boosts. Just thrust them deep into your systems and watch the magic happen. However, when you watch the demo videos and use cases, it’s easy to understand why most people scratch their heads—just as they did with the Humane Pin and the Rabbit. At this point, they are just setting fire to VC money, hoping that a use case will rise from the ashes.
All joking aside, the tools and their usefulness aren’t the subject of this post. I want to focus on the architectural shift and new exposures we create with these tools. This trend will continue regardless of the use case, tech company, or startup.
Note: I’m on vacation and haven’t followed up on Apple’s AI announcements from WWDC, hence the lack of mention here. I wrote most of this post before leaving on vacation.
New High-Value Targets
One of the things that saves us when we have a breach is that all of our data is rarely collected in a single place. Even in particularly bad breaches, let’s say, of your financial institution, there isn’t also data about your healthcare records, GPS location, browser history, etc. Our world is filled with disparate and disconnected data sources, and this disconnection provides some benefits. This means that breaches may be bad but not as bad as they could have been.

A simple way of looking at it is to say our digital data reality consists of web, cloud, and local data. But even in these different categories, there’s still plenty of segmentation. For example, it’s not like website A knows you have an account on website B. Even locally on your computer or device, application A might not know that application B is installed and much less have access to its data. There are exceptions to this, like purposeful integrations between sites, SSO providers, etc., but the point holds for the most part.
With new personal AI systems, we are about to centralize much of this previously decentralized data, collapsing divisions between web, cloud, and local data, making every breach more impactful. The personal AI paradigm potentially makes all data local and accessible. But it gets worse. This new centralized paradigm of personal AI mixes not only sensitive and non-sensitive data but also trusted and untrusted data together in the same context. We’ve known not to do this since the dawn of information security.
This new centralized paradigm of personal AI mixes not only sensitive and non-sensitive data but also trusted and untrusted data together in the same context.
It’s known with the generative AI systems today that if you have untrusted data in your system, you can’t trust the output. People have used indirect prompt injection attacks to compromise all sorts of implementations. We are now discarding this knowledge, giving these systems more access, privileges, and data. Remember, breaches are as bad as the data and functionality exposed, and we are removing the safety keys from the launch button.
How Centralization Happens
I’ve talked about centralizing data at a high level, but what does that look like in practice? Let’s illustrate this with a simple diagram.
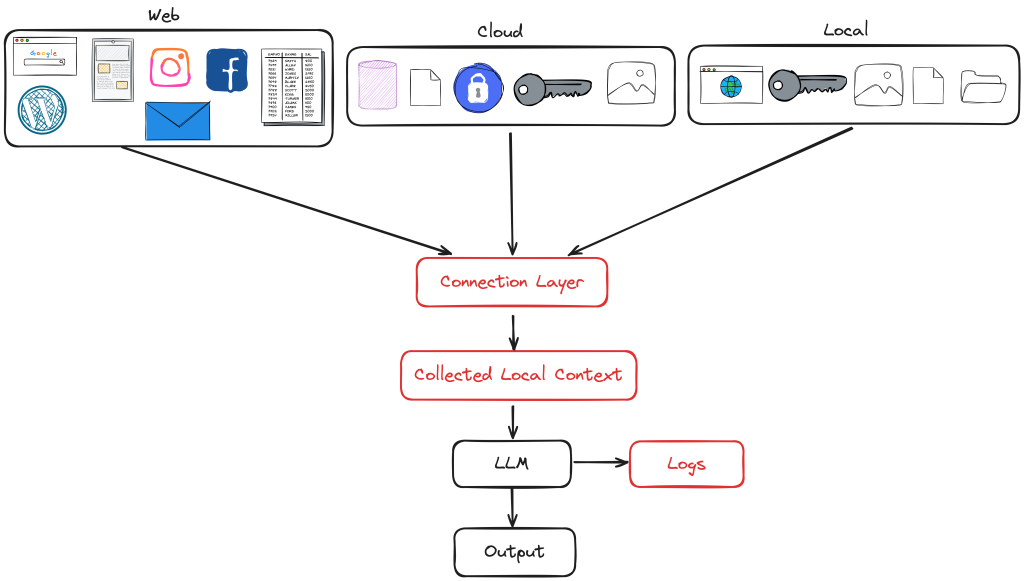
We can envision our three buckets of web, cloud, and local data tied together through a connection layer. This layer is responsible for the connections, credentials, login macros, schedulers, and other methods to maintain connections with applications and data sources. The connection layer allows data from all of these sources to be collected locally for the context necessary for use with the LLM. This can either be done at request time or proactively collected for availability. This connection layer creates a local context that threads down the segmentation between the data sources.
The implementation specifics will depend on the tool, and new tools may implement new architectures. So, it’s helpful to back up and consider what’s happening with these tools. We have a tool on our systems that runs with elevated privileges, needs access to a wide variety of data, and takes actions on our behalf. In theory, these systems could access all the same things we have access to. This is our starting point.
These systems will have access to external data, such as cloud and web data and local system data (data on your machine). Your system could collect data from log files, outputs from applications, or even things such as browser history. Of course, they may also have additional logging, such as recording all activity on your system, like Microsoft’s Recall feature, and storing it neatly in a plain text database which now, due to backlash, has caused changes and now, delays.
Having access to data is only one piece of the puzzle. These systems need to contextualize this information to actually do something with it. Your data will need to be both available and readable. This means it’ll need to be collected for this contextualization.
For example, if you ask your personal AI a question like:
What is the best way to invest the amount of money I have in my savings account, according to the Mega Awesome Investment Strategy?The LLM needs two specific pieces of context to begin formulating an answer to the question. It needs to know how much money you have in your savings account and what the Mega Awesome Investment Strategy is. The LLM queries your financial institution to pull back the amount of money in your savings account. It then needs data about the strategy. Maybe it invokes a web search to find the result and use that as part of the context (let’s ignore all the potential pitfalls of this for a moment.) It uses these two pieces of data as context, either sending them off to a cloud-hosted LLM or using a local LLM.
The data can be queried at runtime or periodically synced to your computer for speed and resistance to service downtime. All this data, including synced data, credentials, previous prompts, and much more, will be stored locally on your system and possibly synced to the cloud. Since this data needs to be readable for LLMs, it will most likely be stored in plaintext, counting on other controls to provide protection. Your most sensitive data is collected in a single place, conveniently tied together, waiting for an attacker to compromise it.
Even scarier, we will get to a point where we can run this query:
Implement the Mega Awesome Investment Strategy with the money I have in my savings account.This will leave us with systems that not only use the collected data but also take action on our behalf—operating as and taking action as us. I’ve mentioned before that we are getting to a point where we may never actually know why our computers are doing anything, accessing the files they are, or even taking the actions they take. This condition makes our computers far more opaque than they are today.
This example was just a simple question with one piece of financial data, but these systems are generalized and will have context for whatever data sources are connected. There will be a push to connect them to everything. Healthcare, browsing data, emails, you name it, all stored conveniently in a single place, making any breach far worse. It’s like collecting all the money from the regional vaults and putting it behind the window in front of the main bank.
There’s Gold In That Thar Data
If data is gold, this is an absolute gold mine. As a matter of fact, this data is so valuable it will be hard for companies to keep their hands off of it in a new data gold fever. So, although up to this point, I’ve been talking about malicious attackers having access to this data, it’s also the case that tech companies will want this data as well, and all efforts will be made to access it and use it. This will be through both overt and covert methods. Turning settings on by default, fine print in user agreements, etc.
If you think the startup developing the tool says they respect my privacy and won’t use this data for anything, think again. Even if this statement were true, wait until they get acquired.
Conclusion
First things first, we need to ask what we get from these integrations. Are the benefits worth the risks of security and privacy exposures created by these new high-value targets? The answer to this question will be a personal choice, but for a vast majority, the answer will be no. At this point, there is still more hype than help.
Authentication, authorization, and data protection need to be key in these new architectures. Not only that, but we must put our own guardrails in place to protect our most sensitive data. This is all going to be additional work for the end user. These systems act as us accessing our most sensitive data. Anyone able to interact with them is basically us. There are no secrets between you and your personal AI. Companies also need to ensure that users understand the potential dangers and pitfalls and provide the ability to turn these features off.
There are no secrets between you and your personal AI.
Tech companies must start taking this problem seriously and acknowledging the new high-value targets they create with these new paradigms. If they are going to shove this technology into every system, making it unavoidable, then it needs to have a bare minimum level of safety and security. It’s one of the reasons I’ve been harping on my SPAR categories as a baseline starting point.
